
blotdb #
1. 简介 #
boltdb是一个纯go编写的支持事务的文件型单机kv数据库。 其具有以下特点:
- 单机部署:不需要考虑CAP
- 支持事物:仅允许多个只读事务和最多一个读写事务同时运行
- 索引结构:因为是kv型的数据库,所以天然地只有主键索引(B+树实现),减少了磁盘IO
- 缓存管理:仅管理写缓存,利用mmap管理读缓存
2. 核心数据结构分析 #
先从介绍一下bolt使用的一些底层的数据结构。
- db
- page
- node
- bucket
- cursor
1. db #
在boltdb中,它的数据全部都是存储在文件上,一个db对应一个真实的磁盘文件。
func main() {
db, err := bolt.Open("my.db", 0600, nil)
if err != nil {
log.Fatal(err)
}
defer db.Close()
}执行完上面的代码后,可以看到根目录多一个my.db的文件
ll
total 40
-rw-r--r-- 1 chuckchen staff 173B Nov 16 10:56 main.go
-rw------- 1 chuckchen staff 16K Nov 16 10:57 my.db2. page #
在具体的磁盘文件中,boltdb又是以page为单位来读取和写入数据库的,即数据在磁盘上是以page为单位进行存储的,page的大小与操作系统保持一致(一般为4k)。
其中每个page又由 页头数据 + 真实数据 组成,页的数据结构如下:
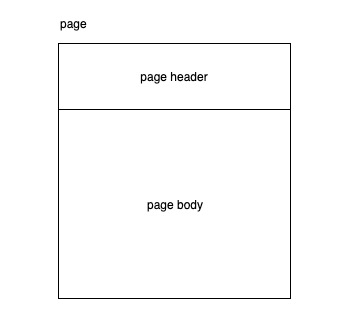
page的数据定义如下:
//page.go
type pgid uint64
type page struct {
//page header
id pgid //页id
flags uint16 //标记位,用来表示页的类型,枚举下面再介绍
count uint16 //个数,用来记录page中元素的个数
overflow uint32 //当遇到体积巨大,单个page无法装下的数据时,会溢出到其他paage,overflow记录溢出总数
//page body
ptr uintptr //指向page数据的内存地址,该字段仅在内存中存在
}page类型的枚举值如下:
//page.go
const (
branchPageFlag = 0x01 //分支节点页 存储索引信息(页号、元素key值),即B+树的非叶子节点
leafPageFlag = 0x02 //叶子节点页 存储数据信息(页号,kv值),即B+树的
metaPageFlag = 0x04 //存储数据库的元信息(空闲列表页id、放置桶的根页等)
freelistPageFlag = 0x10 //存储哪些页是空闲页,可以用来后续分配空间时,优先考虑分配
)下面再具体看看每种page类型分别有什么作用。
2.1. meta #
meta page 记录 Bolt 实例的所有元数据,它告诉用户这是什么文件以及如何解读这个文件,具体结构如下:
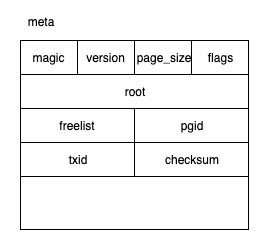
//db.go
type meta struct {
magic uint32 //随机数,用来确定该文件是一个bolt数据库文件(另一种文件起始位置拥有相同数据的可能性极低)
version uint32 //表明该文件所属的bolt版本,便于日后做兼容与迁移
pageSize uint32 //页大小 与操作系统一致
flags uint32 //保留字段,未使用
root bucket //bolt实例所有索引和原数据被组织成一个树形结构,root 就是根节点
freelist pgid //bolt删除数据时可能出现富余的空间,这些空间会被记录在freelist中备用
pgid pgid //下一个要被分配的 page 的 id,取值大于已分配的所有 pages 的 id
txid txid //下一个要被分配的事务 id。事务 id 单调递增,可以被理解为事务执行的逻辑时间
checksum uint64 //用于确认 meta page 数据本身的完整性,保证读取的是上一次写入的数据
}将meta写入page代码如下:
func (m *meta) write(p *page) {
if m.root.root >= m.pgid {
panic(fmt.Sprintf("root bucket pgid (%d) above high water mark (%d)", m.root.root, m.pgid))
} else if m.freelist >= m.pgid {
panic(fmt.Sprintf("freelist pgid (%d) above high water mark (%d)", m.freelist, m.pgid))
}
//page id 要么是0,要么是1 这取决于 meta.txid
p.id = pgid(m.txid % 2)
//设置page类型
p.flags |= metaPageFlag
// 计算checksum
m.checksum = m.sum64()
//将met拷贝到page.ptr
m.copy(p.meta())
}2.2 freelist #
freelist 记录着一个有序的 page id 列表:

freelist的数据结构如下:
//freelist.go
type freelist struct {
ids []pgid // 可以用来分配的空闲页id
pending map[txid][]pgid // 将来很快能被释放的空闲页,部分事务可能在读或在写
cache map[pgid]bool // 一个map,用来快速判断某个页是否为空闲页
}将空闲列表转换成页信息,代码如下:
// write writes the page ids onto a freelist page. All free and pending ids are
// saved to disk since in the event of a program crash, all pending ids will
// become free.
func (f *freelist) write(p *page) error {
// Combine the old free pgids and pgids waiting on an open transaction.
// Update the header flag.
p.flags |= freelistPageFlag
//page.count是一个uint16类型的数字,这也意味着它的最大值只能到 2^16 = 65536, 如果空闲页的个数
//超过65535,则需要将page.prt中的第一个字节来存储其他的空闲页个数,同时将p.count设置为0xFFFF
lenids := f.count() //计算空闲列表的总数
if lenids == 0 {
p.count = uint16(lenids)
} else if lenids < 0xFFFF { // 不超过65535
p.count = uint16(lenids)
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[:])
} else { //超过65535
p.count = 0xFFFF
((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[0] = pgid(lenids)
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[1:])
}
return nil
}todo…
2.3. branch #
bolt 利用 B+ 树存储索引和键值数据本身,这里的 branch 指的就是 B+ 树的分支节点。 branch 需要存储大小不同键值数据,布局如下:
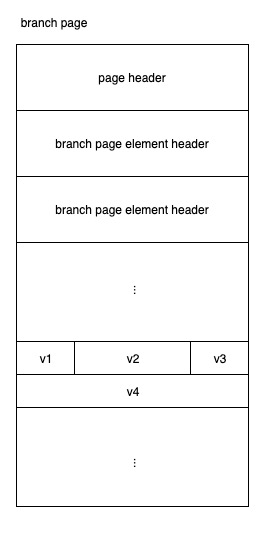
分支节点在存储时,一个分支节点页会存储多个分支页元素,即branchPageElement,这个信息可以记作为分支页元素元信息。元信息中定义了具体该元素的页(pgid)、改元素所指向的页中
type branchPageElement struct {
pos uint32 //该元信息与真实key之间的偏移
ksize uint32 //key的长度
pgid pgid //该元素的页id
}Todo…
2.4 leaf #
叶子节点主要用来存储实际的数据,leaf里存的是key + value,其布局如下:
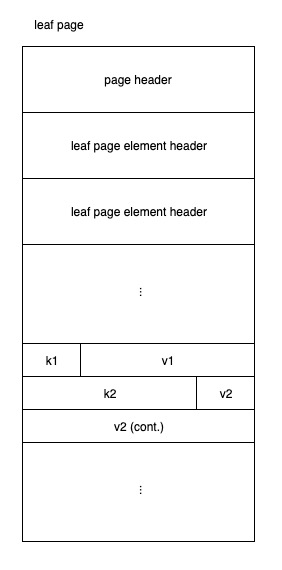
//page.go
type leafPageElement struct {
flags uint32 //用来判断是子桶叶子节点元素还是普通的k/v叶子节点元
pos uint32 //偏移位置
ksize uint32 //key的大小
vsize uint32 //value的大小
}
//叶子节点的key
func (n *leafPageElement) key() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
//pos - pos+ksize
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize:n.ksize]
}
//叶子节点的value
func (n *leafPageElement) value() []byte {
buf := (*[maxAllocSize]byte)(unsafe.Pointer(n))
//pos+ksize - pos+ksize+vsize
return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos+n.ksize]))[:n.vsize:n.vsize]
}
//从page里提取某个具体的叶子节点元素
func (p *page) branchPageElement(index uint16) *branchPageElement {
return &((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[index]
}
//从page里提取所有的叶子节点元素
func (p *page) leafPageElements() []leafPageElement {
if p.count == 0 {
return nil
}
return ((*[0x7FFFFFF]leafPageElement)(unsafe.Pointer(&p.ptr)))[:]
}3. node #
在磁盘中数据是用page来表示的,但是在内存中数据是用node来表示的,node可以说是解序列化后的page。
//node.go
type node struct {
bucket *Bucket //内联的bucket 下面会介绍
isLeaf bool //区分是分支节点还是叶子节点
unbalanced bool //值为true的话,需要考虑页合并
spilled bool //值为true的话,需要考虑页分裂
key []byte //最小的key(第一个inode的key,inode是有序存储的)
pgid pgid //node关联的 page id
parent *node //父parent
children nodes //子节点 如果是叶子节点这个字段为空
inodes inodes //inode表示内部节点 inodes表示改节点存储的若干个kv值 inode会在 B+ 树中进行路由——二分查找时使用。
}
type nodes []*node
func (s nodes) Len() int { return len(s) }
func (s nodes) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
func (s nodes) Less(i, j int) bool { return bytes.Compare(s[i].inodes[0].key, s[j].inodes[0].key) == -1 }
//内部节点定义
type inode struct {
flags uint32 // 表示是否是子桶叶子节点还是普通叶子节点。如果flags值为1表示子桶叶子节点,否则为普通叶子节点
pgid pgid //当inode为分支元素时,pgid才有值,为叶子元素时,则没值
key []byte
value []byte //当inode为分支元素时,value为空,为叶子元素时,才有值
}
type inodes []inode
//将page转换为内存中的node
func (n *node) read(p *page) {
n.pgid = p.id
n.isLeaf = ((p.flags & leafPageFlag) != 0)
n.inodes = make(inodes, int(p.count))
for i := 0; i < int(p.count); i++ {
inode := &n.inodes[i]
if n.isLeaf { //如果是叶子节点
//获取叶子节点元素
elem := p.leafPageElement(uint16(i))
//子桶 or 叶子节点
inode.flags = elem.flags
//读取k/v
inode.key = elem.key()
inode.value = elem.value()
} else {//如果是分支节点
//获取分支节点元素
elem := p.branchPageElement(uint16(i))
//记录页id
inode.pgid = elem.pgid
//读取k
inode.key = elem.key()
}
_assert(len(inode.key) > 0, "read: zero-length inode key")
}
// Save first key so we can find the node in the parent when we spill.
if len(n.inodes) > 0 {
//将该页的第一个key放入node.key中,以便父节点以此作为索引进行查找和路由
n.key = n.inodes[0].key
_assert(len(n.key) > 0, "read: zero-length node key")
} else {
n.key = nil
}
}
//将node转换为page
func (n *node) write(p *page) {
// Initialize page.
//判断是叶子节点还是分支节点
if n.isLeaf {
p.flags |= leafPageFlag
} else {
p.flags |= branchPageFlag
}
if len(n.inodes) >= 0xFFFF {
panic(fmt.Sprintf("inode overflow: %d (pgid=%d)", len(n.inodes), p.id))
}
p.count = uint16(len(n.inodes))
// Stop here if there are no items to write.
if p.count == 0 {
return
}
// Loop over each item and write it to the page.
b := (*[maxAllocSize]byte)(unsafe.Pointer(&p.ptr))[n.pageElementSize()*len(n.inodes):]
//遍历indoes 将inode信息写入page.ptr中
for i, item := range n.inodes {
_assert(len(item.key) > 0, "write: zero-length inode key")
// Write the page element.
if n.isLeaf {
//构建一个page的叶子节点元素
elem := p.leafPageElement(uint16(i))
//将相关字段信息写入元素中
elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem)))
elem.flags = item.flags
elem.ksize = uint32(len(item.key))
elem.vsize = uint32(len(item.value))
} else {
//构建一个page的分支节点元素
elem := p.branchPageElement(uint16(i))
//将相关字段信息写入元素中
elem.pos = uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem)))
elem.ksize = uint32(len(item.key))
elem.pgid = item.pgid
_assert(elem.pgid != p.id, "write: circular dependency occurred")
}
//如果kv值太大 超过了剩下的可分配的空间,那么需要重新分配空间
klen, vlen := len(item.key), len(item.value)
if len(b) < klen+vlen {
b = (*[maxAllocSize]byte)(unsafe.Pointer(&b[0]))[:]
}
//将数据(kv)放到 page的body里
copy(b[0:], item.key)
b = b[klen:]
copy(b[0:], item.value)
b = b[vlen:]
}
// DEBUG ONLY: n.dump()
}
//put 写入kv数据
func (n *node) put(oldKey, newKey, value []byte, pgid pgid, flags uint32) {
if pgid >= n.bucket.tx.meta.pgid {
panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", pgid, n.bucket.tx.meta.pgid))
} else if len(oldKey) <= 0 {
panic("put: zero-length old key")
} else if len(newKey) <= 0 {
panic("put: zero-length new key")
}
// 查找key所在的位置
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, oldKey) != -1 })
// Add capacity and shift nodes if we don't have an exact match and need to insert.
exact := (len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey))
if !exact {
//key如果不存在就插入
n.inodes = append(n.inodes, inode{})
copy(n.inodes[index+1:], n.inodes[index:])
}
//修改(新增) key对应的value值
inode := &n.inodes[index]
inode.flags = flags
inode.key = newKey
inode.value = value
inode.pgid = pgid
_assert(len(inode.key) > 0, "put: zero-length inode key")
}
//node的分裂与合并。。。todo4. bucket #
bucket是一堆kv对的集合,如果db代表关系型数据库中的**“库”,那么bucket则代表关系型数据库中的“表”**。bucket还支持无限嵌套,即bucket里可以创建子bucket,为开发者归类数据提供更灵活的方案。一个bucket代表一颗完整的 b+树。
//bucket.go
type Bucket struct {
*bucket // 内联的bucket 下面会介绍到
tx *Tx // 关联的事物 事务后面再讲 先忽略
buckets map[string]*Bucket // 当前桶的子桶
page *page // 内联模式下 指内联page的指针
rootNode *node // 根桶页对应的node
nodes map[pgid]*node // 在这个bucket下 在内存中的node
// Sets the threshold for filling nodes when they split. By default,
// the bucket will fill to 50% but it can be useful to increase this
// amount if you know that your write workloads are mostly append-only.
//
// This is non-persisted across transactions so it must be set in every Tx.
//填充率
FillPercent float64
}
type bucket struct {
root pgid // 根桶(👇会解释什么是根桶)的page id
sequence uint64 // 单调递增的序列号
}在初始化新的实例时bolt会创建一个page (pgid=3) 来存储根桶,根桶指向一个空的 leaf page,这个 leaf page 将成为所有用户创建的子桶及kv数据的容器,在db.init()中可以看到创建pgid = 3 的过程。
func (db *DB) init() error {
//
...
// Create two meta pages on a buffer.
...
// Write an empty freelist at page 3.
...
// pgid = 3 的这一页用来存放root nod
p = db.pageInBuffer(buf[:], pgid(3))
p.id = pgid(3)
p.flags = leafPageFlag
p.count = 0
// Write the buffer to our data file.
...
return nil
}在正常的情况下,每一个bucket都有自己独立的page来构造自己的一颗 b+ 树,但是当一个db内的bucket非常多,但是每个bucket的数据量都非常小的时候,就会产生内部碎片,浪费存储空间。为了解决这个问题,boltdb采用inline-bucket的模式。inline-bucket桶不会占用单独的page,而是将bucket的数据放inline-page里面,每个inline-page普通的page一样有 page header、element headers、data,但在存储时它将被序列化成一般的二进制数据与桶名一起作为普通键值数据储存。
初始化完成后如下图所示:
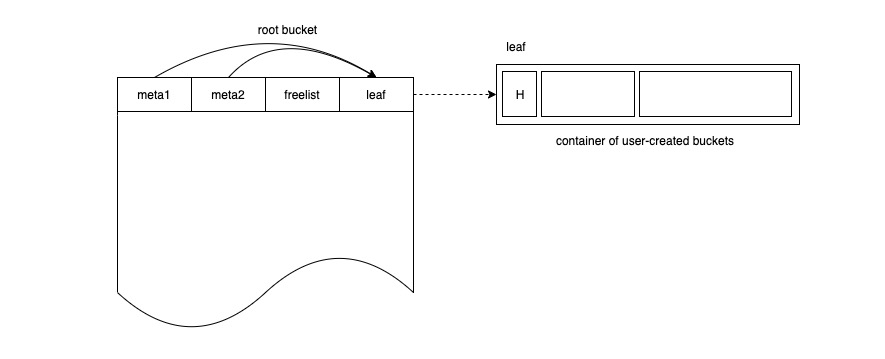
初始化完成后创建一个名叫“b1”的桶,此时桶中的数据量还太小,所以创建的是inline-bucket,创建完桶后如图所示:
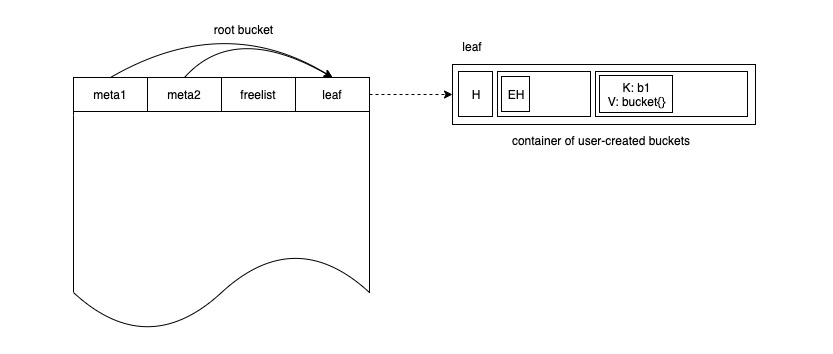
往b1桶里插入{k1, v1},完成后如下图所示:
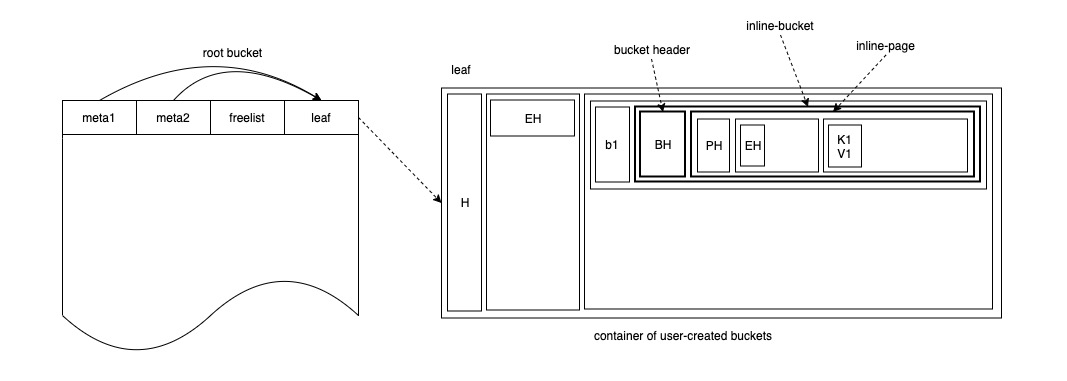
当b1桶中的数据到一定量,超过 inline-bucket 大小时,inline-bucket 就会转化成正常的bucket,并且能够分配到属于自己的page。
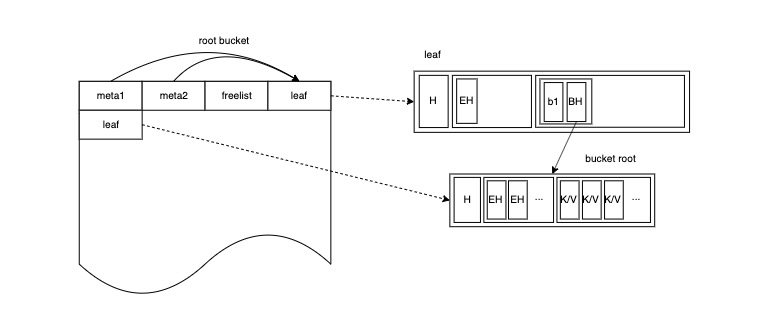
插入更多的键值数据,b1 桶就会长成一棵更茂盛的 B+ 树:
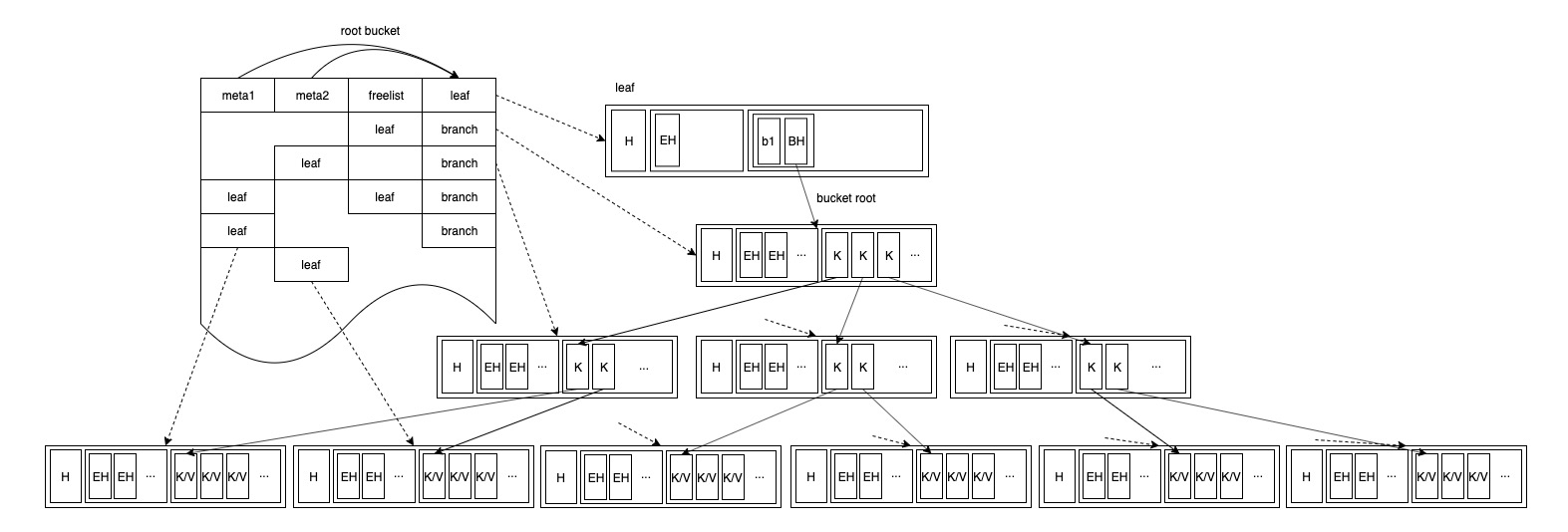
如果使用者在同一个db里创建更多像b1一样的bucket,直到一个 leaf page 无法容纳根桶的所有子节点,这时 root bucket 自身也将长成一棵更茂盛的 b+ 树:
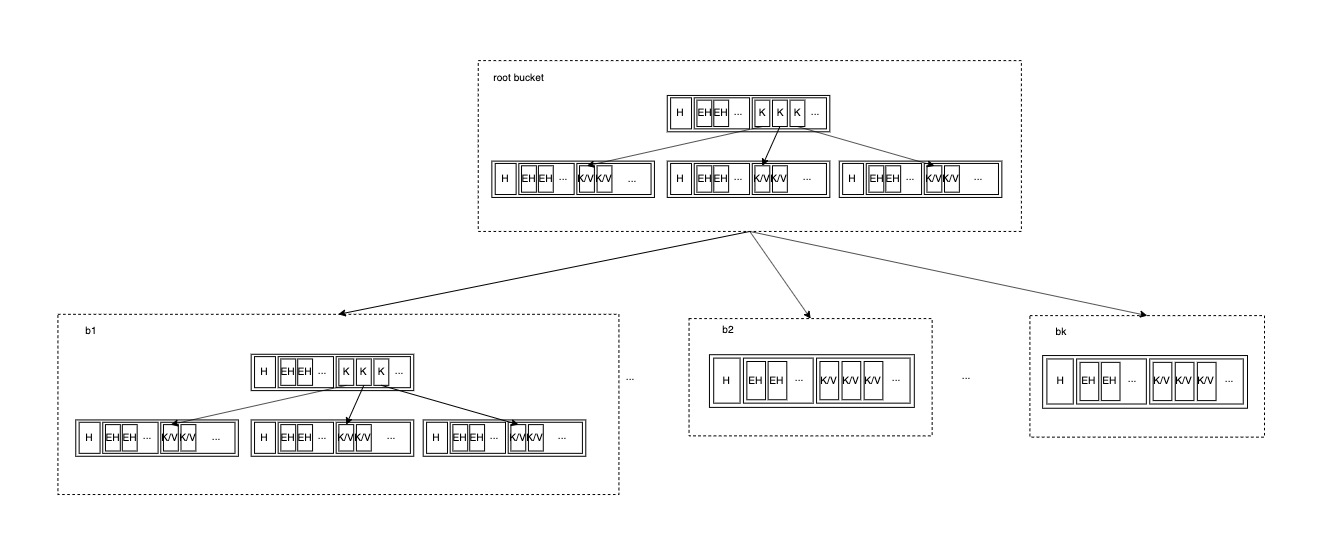
5. cursor #
前面说到bucket是一颗b+树,用来存储db数据,那么就必定需要对这颗二叉树进行增删改查。cursor即下标,cursor的作用是在bucket上找到对应的数据,然后再进行操作。简而言之对bucket这颗b+树上的遍历/查找功能由cursor来完成。
下面代码的功能是创建 一个与这个bucket相关的cursor。
//bucket.go
//创建的cursor只在事务范围之内有效
//事务结束后不要再使用这个cursor
func (b *Bucket) Cursor() *Cursor {
// Update transaction statistics.
b.tx.stats.CursorCount++
// Allocate and return a cursor.
return &Cursor{
bucket: b,
stack: make([]elemRef, 0),
}
}cursor的数据结构及一些方法如下所示:
//cursor.go
type Cursor struct {
bucket *Bucket //对应的bucket
//在cursor的使用过程中,通常不会一次性遍历完所有数据,而是用
//stack这个字段来记录所查询过程中经历的路径(也可以理解为搜索的路径)
//以方便cursor记录上一次所在的位置信息
stack []elemRef
}
//元素引用
type elemRef struct {
page *page
node *node
index int
}
//判断是否为叶子节点
func (r *elemRef) isLeaf() bool {
if r.node != nil {
return r.node.isLeaf
}
return (r.page.flags & leafPageFlag) != 0
}
//元素个数
func (r *elemRef) count() int {
if r.node != nil {
return len(r.node.inodes)
}
return int(r.page.count)
}针对一颗b+树,cursor提供了两种类型的方法:
- 顺序访问/遍历:First、Last、Next、Prev
- 随机访问/检索:Seek
//根据key返回对应的kv值
func (c *Cursor) Seek(seek []byte) (key []byte, value []byte) {
//查找对应的kv flags代表是嵌套子桶还是普通kv
k, v, flags := c.seek(seek)
// If we ended up after the last element of a page then move to the next one.
if ref := &c.stack[len(c.stack)-1]; ref.index >= ref.count() {
k, v, flags = c.next()
}
if k == nil { //对应的key不存在
return nil, nil
} else if (flags & uint32(bucketLeafFlag)) != 0 { //key存储的是嵌套的子桶 所以返回的value是nil
return k, nil
}
return k, v
}
//内部的seek方法
func (c *Cursor) seek(seek []byte) (key []byte, value []byte, flags uint32) {
_assert(c.bucket.tx.db != nil, "tx closed")
// Start from root page/node and traverse to correct page.
c.stack = c.stack[:0]
c.search(seek, c.bucket.root)
ref := &c.stack[len(c.stack)-1]
// 没找到
if ref.index >= ref.count() {
return nil, nil, 0
}
// If this is a bucket then return a nil value.
return c.keyValue()
}
//内部的search方法 使用递归二分查找对应的key 这是seek中最核心的方法
func (c *Cursor) search(key []byte, pgid pgid) {
//获取pgid对应的 node 或者 page
p, n := c.bucket.pageNode(pgid)
if p != nil && (p.flags&(branchPageFlag|leafPageFlag)) == 0 {
panic(fmt.Sprintf("invalid page type: %d: %x", p.id, p.flags))
}
//记录路径 放到stack里
e := elemRef{page: p, node: n}
c.stack = append(c.stack, e)
// 如果已经是b+树叶子节点了
if e.isLeaf() {
//
c.nsearch(key)
//结束递归
return
}
//在遍历过程中 有可能遍历到的当前分支节点数据并没有在内存中,此时就需要从page中加载数据遍历。所以在遍历过程中,优先在node中找,如果node为空的时候才会采用page来查找
if n != nil {
c.searchNode(key, n)
return
}
c.searchPage(key, p)
}
//pageNode 查找pgid对应的在内存中的node 或者 是底层的page
func (b *Bucket) pageNode(id pgid) (*page, *node) {
// Inline buckets have a fake page embedded in their value so treat them
// differently. We'll return the rootNode (if available) or the fake page.
if b.root == 0 { //b.root == 0 代表内联模式
if id != 0 {
panic(fmt.Sprintf("inline bucket non-zero page access(2): %d != 0", id))
}
if b.rootNode != nil {
return nil, b.rootNode
}
return b.page, nil
}
// 从这个bucket存在内存中的node中查找
if b.nodes != nil {
if n := b.nodes[id]; n != nil {
return nil, n
}
}
// 最后从事务里查找。。。????
return b.tx.page(id), nil
}
// searchNode 在node里查找具体的key
func (c *Cursor) searchNode(key []byte, n *node) {
var exact bool
index := sort.Search(len(n.inodes), func(i int) bool {
// TODO(benbjohnson): Optimize this range search. It's a bit hacky right now.
// sort.Search() finds the lowest index where f() != -1 but we need the highest index.
ret := bytes.Compare(n.inodes[i].key, key)
if ret == 0 {
exact = true
}
return ret != -1
})
if !exact && index > 0 {
index--
}
c.stack[len(c.stack)-1].index = index
// 递归查找下一页
c.search(key, n.inodes[index].pgid)
}
// searchPage 在page里查找具体的key
func (c *Cursor) searchPage(key []byte, p *page) {
// 二分查找所有的elements
inodes := p.branchPageElements()
var exact bool
index := sort.Search(int(p.count), func(i int) bool {
// TODO(benbjohnson): Optimize this range search. It's a bit hacky right now.
// sort.Search() finds the lowest index where f() != -1 but we need the highest index.
ret := bytes.Compare(inodes[i].key(), key)
if ret == 0 {
exact = true
}
return ret != -1
})
if !exact && index > 0 {
index--
}
c.stack[len(c.stack)-1].index = index
// 递归查找下一页
c.search(key, inodes[index].pgid)
}
// nsearch 在叶子节点(stack的栈顶)查找对应的key
func (c *Cursor) nsearch(key []byte) {
//从栈顶获取叶子节点对应的 page node
e := &c.stack[len(c.stack)-1]
p, n := e.page, e.node
// 如果有node 就直接从node中二分查找
if n != nil {
index := sort.Search(len(n.inodes), func(i int) bool {
return bytes.Compare(n.inodes[i].key, key) != -1
})
e.index = index //标记索引位置
return
}
// 从page中二分查找
inodes := p.leafPageElements()
index := sort.Search(int(p.count), func(i int) bool {
return bytes.Compare(inodes[i].key(), key) != -1
})
e.index = index //标记索引位置
}上面讲的方法Seek方法是随机访问,下面讲顺序查找的几种方法。
First()用于找到bucket里的第一个数据项。
func (c *Cursor) First() (key []byte, value []byte) {
_assert(c.bucket.tx.db != nil, "tx closed")
//清空stack
c.stack = c.stack[:0]
p, n := c.bucket.pageNode(c.bucket.root)
c.stack = append(c.stack, elemRef{page: p, node: n, index: 0})
//index设为0 将cursor移动至第一个叶子节点并且index = 0的位置
c.first()
// If we land on an empty page then move to the next value.
// https://github.com/boltdb/bolt/issues/450
//......
if c.stack[len(c.stack)-1].count() == 0 {
c.next()
}
//从栈顶的ref(page 或者 node)里获取kv
k, v, flags := c.keyValue()
//嵌套子桶 or kv值
if (flags & uint32(bucketLeafFlag)) != 0 {
return k, nil
}
return k, v
}
func (c *Cursor) first() {
for {
// Exit when we hit a leaf page.
var ref = &c.stack[len(c.stack)-1]
if ref.isLeaf() {
break //叶子节点 退出
}
// 当前节点是非叶子节点 继续往下一个 page 或者 node 找
var pgid pgid
if ref.node != nil {
pgid = ref.node.inodes[ref.index].pgid
} else {
pgid = ref.page.branchPageElement(uint16(ref.index)).pgid
}
p, n := c.bucket.pageNode(pgid)
c.stack = append(c.stack, elemRef{page: p, node: n, index: 0})
}
}Last()用于找到bucket里的最后一个数据项。
func (c *Cursor) Last() (key []byte, value []byte) {
_assert(c.bucket.tx.db != nil, "tx closed")
c.stack = c.stack[:0]
p, n := c.bucket.pageNode(c.bucket.root)
ref := elemRef{page: p, node: n}
//index = ref.count()-1
ref.index = ref.count() - 1
c.stack = append(c.stack, ref)
c.last()
k, v, flags := c.keyValue()
if (flags & uint32(bucketLeafFlag)) != 0 {
return k, nil
}
return k, v
}
func (c *Cursor) last() {
for {
// Exit when we hit a leaf page.
ref := &c.stack[len(c.stack)-1]
if ref.isLeaf() {
break
}
// Keep adding pages pointing to the last element in the stack.
var pgid pgid
if ref.node != nil {
pgid = ref.node.inodes[ref.index].pgid
} else {
pgid = ref.page.branchPageElement(uint16(ref.index)).pgid
}
p, n := c.bucket.pageNode(pgid)
var nextRef = elemRef{page: p, node: n}
nextRef.index = nextRef.count() - 1
c.stack = append(c.stack, nextRef)
}
}Next() Prev() 分析实现
func (c *Cursor) Next() (key []byte, value []byte) {
_assert(c.bucket.tx.db != nil, "tx closed")
k, v, flags := c.next()
if (flags & uint32(bucketLeafFlag)) != 0 {
return k, nil
}
return k, v
}
//
func (c *Cursor) next() (key []byte, value []byte, flags uint32) {
for {
//这里从栈顶往栈底找 如果当前cursor已经处于二叉树节点的最后一个位置,
//那么需要回退到遍历路径的上一个节点,然后再继续查找。
var i int
for i = len(c.stack) - 1; i >= 0; i-- {
elem := &c.stack[i]
if elem.index < elem.count()-1 {
//找下一个位置
elem.index++
break
}
}
//当前游标已经在最后一个位置 说明没有next了,返回 nil
if i == -1 {
return nil, nil, 0
}
//去掉那些已经处于末尾位置的节点
c.stack = c.stack[:i+1]
//根据当前栈的信息查找
//如果是叶子节点,first()啥都不做,直接退出。返回elem.index+1的数据
//非叶子节点的话,需要移动到stack中最后一个路径的第一个元素
c.first()
// If this is an empty page then restart and move back up the stack.
// https://github.com/boltdb/bolt/issues/450
if c.stack[len(c.stack)-1].count() == 0 {
continue
}
return c.keyValue()
}
}
//
func (c *Cursor) Prev() (key []byte, value []byte) {
_assert(c.bucket.tx.db != nil, "tx closed")
// Attempt to move back one element until we're successful.
// Move up the stack as we hit the beginning of each page in our stack.
for i := len(c.stack) - 1; i >= 0; i-- {
elem := &c.stack[i]
if elem.index > 0 {
//查找前一个位置
elem.index--
break
}
c.stack = c.stack[:i]
}
// If we've hit the end then return nil.
if len(c.stack) == 0 {
return nil, nil
}
// 如果当前节点是叶子节点的话,则直接退出了,啥都不做。否则的话移动到新页的最后一个节点
c.last()
k, v, flags := c.keyValue()
if (flags & uint32(bucketLeafFlag)) != 0 {
return k, nil
}
return k, v
}
func (c *Cursor) last() {
for {
// Exit when we hit a leaf page.
ref := &c.stack[len(c.stack)-1]
if ref.isLeaf() {
break
}
// Keep adding pages pointing to the last element in the stack.
var pgid pgid
if ref.node != nil {
pgid = ref.node.inodes[ref.index].pgid
} else {
pgid = ref.page.branchPageElement(uint16(ref.index)).pgid
}
p, n := c.bucket.pageNode(pgid)
var nextRef = elemRef{page: p, node: n}
nextRef.index = nextRef.count() - 1
c.stack = append(c.stack, nextRef)
}
}Delete() 删除数据
func (c *Cursor) Delete() error {
if c.bucket.tx.db == nil {
return ErrTxClosed
} else if !c.bucket.Writable() {
return ErrTxNotWritable
}
key, _, flags := c.keyValue()
// Return an error if current value is a bucket.
if (flags & bucketLeafFlag) != 0 {
return ErrIncompatibleValue
}
// 从inodes中移除
c.node().del(key)
return nil
}
//从inodes中移除
func (n *node) del(key []byte) {
// Find index of key.
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, key) != -1 })
// Exit if the key isn't found.
if index >= len(n.inodes) || !bytes.Equal(n.inodes[index].key, key) {
return
}
// Delete inode from the node.
n.inodes = append(n.inodes[:index], n.inodes[index+1:]...)
// Mark the node as needing rebalancing.
n.unbalanced = true
}Todo…
3. 事务 #
bolt只支持两种类型的事务:读写事务、只读事务。同一时刻有且只能有一个读写事务执行,但同一时刻允许多个只读事务执行,每个事务都拥有自己的一套一致性视图。bolt如何支持事务的ACID特性?
- A(原子性):在bolt中,数据先写内存,然后再提交时刷盘。如果其中有异常发生,事务就会回滚。同时再加上同一时间只有一个进行对数据执行写入操作。所以它要么写成功提交、要么写失败回滚。也就支持原子性了。
- D(持久性):bolt是一个文件数据库,所有数据最终都保存在文件中,当事务结束时,会对数据进行刷盘。同时,bolt通过冗余一份元数据来进行容错。当事务提交时,如果写入到一半机器挂了,此时数据就会有问题。而当boltdb再次恢复时,会对元数据进行校验和修复。这两点就保证事务中的持久性。
- I(隔离性):bolt在上层支持多个进程以只读的方式打开数据库,一个进程以写的方式打开数据库。在数据库内部中事务支持两种,读写事务和只读事务。这两类事务是互斥的。同一时间可以有多个只读事务执行,或者只能有一个读写事务执行,上述两类事务,在底层实现时,都是保留一整套完整的视图和元数据信息,彼此之间相互隔离。因此通过这两点就保证了隔离性。
- C(一致性): 通过其他三个特性来实现。
type Tx struct {
writable bool //区分是读事务还是写事务
managed bool //
db *DB //事务所属的db
meta *meta
root Bucket
pages map[pgid]*page
stats TxStats
commitHandlers []func() //提交时执行的动作
// WriteFlag specifies the flag for write-related methods like WriteTo().
// Tx opens the database file with the specified flag to copy the data.
//
// By default, the flag is unset, which works well for mostly in-memory
// workloads. For databases that are much larger than available RAM,
// set the flag to syscall.O_DIRECT to avoid trashing the page cache.
WriteFlag int
}
func (tx *Tx) init(db *DB) {
tx.db = db
tx.pages = nil
// 拷贝元信息
tx.meta = &meta{}
db.meta().copy(tx.meta)
// 拷贝跟节点
tx.root = newBucket(tx)
tx.root.bucket = &bucket{}
*tx.root.bucket = tx.meta.root
// 如果是写事务
if tx.writable {
tx.pages = make(map[pgid]*page)
tx.meta.txid += txid(1)
}
}
//db.go
//开启一个事务
func (db *DB) Begin(writable bool) (*Tx, error) {
if writable {
return db.beginRWTx()
}
return db.beginTx()
}
//开启读事务
func (db *DB) beginTx() (*Tx, error) {
// 获取元信息锁
db.metalock.Lock()
// 获取mmap锁
db.mmaplock.RLock()
// Exit if the database is not open yet.
if !db.opened {
db.mmaplock.RUnlock()
db.metalock.Unlock()
return nil, ErrDatabaseNotOpen
}
// 初始化一个事务对象
t := &Tx{}
t.init(db)
// 将这个事务添加的这个db里
db.txs = append(db.txs, t)
n := len(db.txs)
// Unlock the meta pages.
db.metalock.Unlock()
// 更新事务状态
db.statlock.Lock()
db.stats.TxN++
db.stats.OpenTxN = n
db.statlock.Unlock()
return t, nil
}
//开启写事务
func (db *DB) beginRWTx() (*Tx, error) {
// If the database was opened with Options.ReadOnly, return an error.
if db.readOnly {
return nil, ErrDatabaseReadOnly
}
// 写事务的锁 只有当事务结束时才会释放锁 这个锁确保了任意时刻都只能有一个写事务
db.rwlock.Lock()
// 获取元信息锁 以修改元信息里的事务数据
db.metalock.Lock()
defer db.metalock.Unlock()
// Exit if the database is not open yet.
if !db.opened {
db.rwlock.Unlock()
return nil, ErrDatabaseNotOpen
}
// Create a transaction associated with the database.
t := &Tx{writable: true}
t.init(db)
db.rwtx = t
// 找到最小的事务id
var minid txid = 0xFFFFFFFFFFFFFFFF
for _, t := range db.txs {
if t.meta.txid < minid {
minid = t.meta.txid
}
}
if minid > 0 {
//将之前关联事务的id全部释放,因为在只读事务中,没法释放只读事务的页(因为可能
//当前事务已完成,但其他事务还在使用)
db.freelist.release(minid - 1)
}
return t, nil
}
//提交事务
func (tx *Tx) Commit() error {
_assert(!tx.managed, "managed tx commit not allowed")
if tx.db == nil {
return ErrTxClosed
} else if !tx.writable {
return ErrTxNotWritable
}
// TODO(benbjohnson): Use vectorized I/O to write out dirty pages.
// Rebalance nodes。。。重新平衡nodes。。
var startTime = time.Now()
tx.root.rebalance()
if tx.stats.Rebalance > 0 {
tx.stats.RebalanceTime += time.Since(startTime)
}
// spill data onto dirty pages.
startTime = time.Now()
if err := tx.root.spill(); err != nil {
tx.rollback()
return err
}
tx.stats.SpillTime += time.Since(startTime)
// Free the old root bucket.
tx.meta.root.root = tx.root.root
opgid := tx.meta.pgid
// Free the freelist and allocate new pages for it. This will overestimate
// the size of the freelist but not underestimate the size (which would be bad).
tx.db.freelist.free(tx.meta.txid, tx.db.page(tx.meta.freelist))
p, err := tx.allocate((tx.db.freelist.size() / tx.db.pageSize) + 1)
if err != nil {
tx.rollback()
return err
}
if err := tx.db.freelist.write(p); err != nil {
tx.rollback()
return err
}
tx.meta.freelist = p.id
// If the high water mark has moved up then attempt to grow the database.
if tx.meta.pgid > opgid {
if err := tx.db.grow(int(tx.meta.pgid+1) * tx.db.pageSize); err != nil {
tx.rollback()
return err
}
}
// Write dirty pages to disk.
startTime = time.Now()
if err := tx.write(); err != nil {
tx.rollback()
return err
}
// If strict mode is enabled then perform a consistency check.
// Only the first consistency error is reported in the panic.
if tx.db.StrictMode {
ch := tx.Check()
var errs []string
for {
err, ok := <-ch
if !ok {
break
}
errs = append(errs, err.Error())
}
if len(errs) > 0 {
panic("check fail: " + strings.Join(errs, "\n"))
}
}
// Write meta to disk.
if err := tx.writeMeta(); err != nil {
tx.rollback()
return err
}
tx.stats.WriteTime += time.Since(startTime)
// Finalize the transaction.
tx.close()
// Execute commit handlers now that the locks have been removed.
for _, fn := range tx.commitHandlers {
fn()
}
return nil
}Todo …